On the way to BW/4HANA there is no more option to avoid using aDSO’s. The good news is that things are similar as beforehand and there are no disadvantages in using an aDSO instead of a RealTimeCube or a direct Update DSO as an InfoProvider for planning.
One of the biggest advantages of using an aDSO for planning is that there is no need any more in rolling up the plan data (closing the yellow request) before extracting data via a transformation.
Each SAVE event creates a unique request which is immediately available for reporting and extraction.
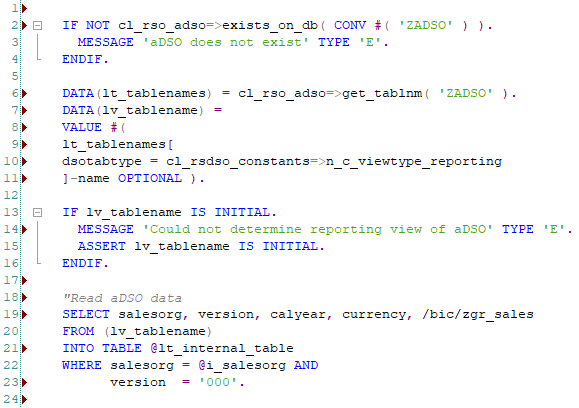
A second advantage of an aDSO is that the data can be easily read via a SQL statement in ABAP. As the data is stored in a table like format in one of the aDSO’s tables and views the only challange is to find the correct table/view to read the data from.
Example of accessing the reporting view of the aDSO named ZADSO:
In the past the direct update DSO was mainly used for key figures which can not be aggregated (e.g. prices, percentages, comments): prices planned on a higher drill-down level were not distributed but copied to each characteristic beneath if the key figure was set up with the aggregation behavior: “No Aggregation (X, If More Than One Value Occurs)”. The query setting for that is “disaggregation copy”.
Most of the other scenarios were kept in an RealTimeCube as this was the first option SAP BW-IP offered since the early stages.
When creating an aDSO for planning you have two options: InfoCube-like or Direct Update aDSO. Which one should you choose?
When planning non-aggregated key figures, you need to use the Direct Update aDSO for planning (template ‘Planning on Direct Update’).
For all other scenarios you have the choice of using the InfoCube-like behavior (see Model Template ->Planning -> Planning on InfoCube-like) or the Direct Update one
(see Model Template ->Planning -> Planning on Direct Update) .
So what is the difference between the two types of planning aDSOs?
In general, there are two major differences. First of all how the data is stored and second how the aDSOs are setup.
Storage of data
InfoCube-like data is stored on SAVE event in the inbound table with the key-figures containing only the delta.
The active table of the aDSO is empty as long as the aDSO data is not activated. To activate the data the aDSO needs to be switched into the load mode. The activation is similar to the compression of real time cubes. All requests are aggregated, and the delta information is lost after activation.
Example:
First save of 1.000 EA
The inbound table of aDSO ZVOLPLA1 -> /BIC/AZVOLPLA11:

Changing the 1.000 EA to 1.500 EA leads to the following records in the inbound table:

The active table of aDSO ZVOLPLA1 : /BIC/AZVOLPLA12 is currently empty.
Data activation will aggregate the inbound table and delete the records from there.
The active table of aDSO ZVOLPLA1 : /BIC/AZVOLPLA12 will hold this record after activation:

The Direct Update aDSO uses only the active table to store the data. No deltas are stored. If a value is changed, the old record gets updated with the new information directly (direct update).
This leads by nature to less data records. No need of switching to load mode as there is no option of activating the data – it is already stored in the active table.
Difference in setting up the planning data model
InfoCube-like aDSO by nature handles all characteristics as key fields.
There is no option in defining key fields (the option in Eclipse is disabled), all of them are part of the key by definition.
To be precise: this holds true in the active table, in the inbound table the key is a unique field REQTSN which holds a timestamp like information followed by a number and a time zone (YYYYMMDDHHMMSS<number><timezome>) along with the record number.
When creating an aggregation level on top of such an aDSO not all characteristics need to be in the aggregation level. When saving data via a planning function or via an input ready query the characteristics which are in the aDSO but not in the aggregation level are kept empty (#).
The direct update aDSO can only be used for planning if all characteristics are set as key fields (exception: characteristic as key-figure can also be used as a non-key field), and you will need to do that manually via the details tab in Eclipse (key components).
For both types of aDSO the aggregation level defines which characteristics are visible in the query or planning function. Not included characteristics will be # on SAVE.
Comparison table
| Feature | Cube-Like Planning aDSO | Direct update Planning aDSO |
|---|---|---|
| Planning features | ||
| Comment / attribute planning (characteristic as key-figure) | Not possible | Possible |
| Price planning (NO2 key-figures) | Not possible | Possible |
| Physical deletion of records | Not possible, you can only “post a combination to zero” on all key-figures. In the future activation might be able do a zero-record-elimination. | Posible, if using the appropriate planning function types / implementations. |
| Data auditing (username and timestamp with every change) | Possible | Not possible |
| Data storage structure | ||
| Key | Active table: all characteristics are key. Inbound table: technical key (request TSN + record number) | Key characteristic set manually, but planning will only work if all characteristics are marked as key – except “characteristic as key-figure” setup. |
| In which table is the data stored? | Data is written into inbound table during planning. Activation will move data from tne inbound to the active table. | Active table only. |
| Maintenance | ||
| Activation of data | Should be done on a regular basis to prevent data volume explosion. The aDSO must be changed to load mode for the time of activation which requires a maintenance ‘downtime’. | Is not necessary and possible. Data is active immediately when written during planning. |
| Selective deletion of data | Possible, in load mode. | Possible, in load mode. |
| Request-wise deletion of data | Possible. | Not possible. |
| User-mode deletion of data | Not possible to physically delete the data without switching to load mode. You can only set all key-figures to 0. | Possible with planning function. |
| Reading the data | ||
| Which table to select from? | Active (suffix 2) and inbound (suffix 1) table. There is a view (suffix 7) to combine them. | Active table (suffix 2) only. |
| How to select? | You might need to aggregate the selected data as for a logical combination there might be multiple records. | No special consideration required. |
| Extraction from the aDSO to other targets | ||
| Full extraction | ||
| Delta extraction | Is easily possible as the change history is available in the inbound table for all requests that have not been activated yet. | Is not possible, as the changes are not tracked. You can only do a full extraction. (With a regulr full extranction into an intermediate changelog-enabled aDSO would however enable you to construct a delta. Deleted record detection requires further considerations.) |
| Memory consumption | ||
| Record count | Will grow with any change, even if no new logical records (combinations) are introduced. Particulare a ‘delete and recalculate’ planning sequence setup can be fatal in terms of data volume. | Same number of physical records as logical records. |
| Bytes consumed | Pseudo-linear with the number of records. | Unfortunately a hidden auto-generated $TREXEXTID column is generated with a concatenated key which often consumes way more data than the actual records themselves due to poor compression. This can especially become a problem if there is a high number of key fields. |
| Verdict | ||
| Advantages | Delta extraction possible. | Simple and transparent storage, price planning and physical record deletion possible. Maintenance-free. |
| Disdvantages | Requires maintenance with downtime. Memory consumption increases with every change of data. | Memory consumption when lot of key fields. |
| Use case | For results of calculation function and possibly manual planning with lot of characteristics. If a simple delta extraction is required. | Price, comment and attribtue planning. Scenarios with few characteristics. |
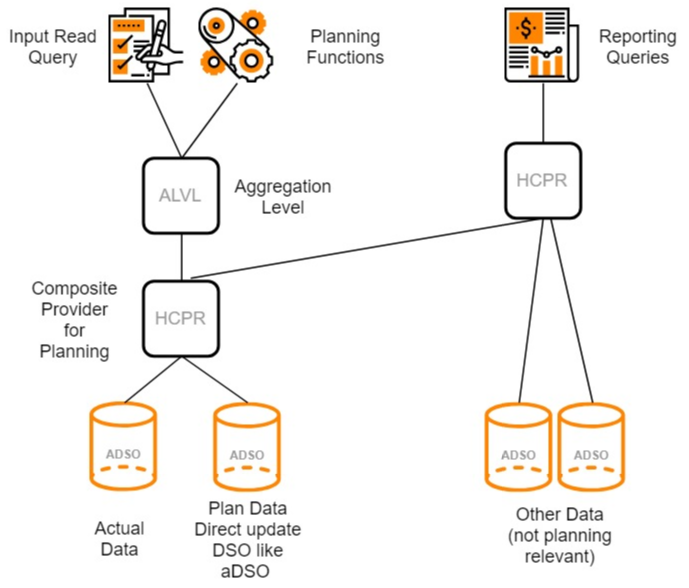
Virtual layers of the data model
Having decided which type of aDSO to go with, you still need set up your virtual data model objects like composite providers and aggregation levels. In general it is recommended to keep the planning model as lean as possible by including only the data and characteristics which are really needed for your planning application. Do not save on the number of composite providers – save on their contents. A composite provider that merged may aDSOs with potentially different data models often ends up having a lot of fields, reducing the performance and making the coding of planning functions intransparent.
On top of the Composite Provider we need an aggregation level – but again there is no need to create multiple ones, unless you have a specific reason.
In case you need additional data for reporting being combined with your plan values a stacked composite provider could be used to achieve that: